The AI Remembers Everything, and a Lot of It Is Wide Open
Vector databases are where AI systems keep the stuff they know. When somebody builds a chatbot that can answer questions about their company docs, those docs get turned into vectors and stored in one of these things. The model out front is the part that talks, the vector database is the actual data behind it. that can answer questions about their company docs, those docs get turned into vectors and stored in one of these things. The model out front is the part that talks, the vector database is the actual data behind it.
I went looking for these using Censys, mostly Qdrant but I checked Weaviate too, and found a lot of them sitting on the public internet with the lock turned off. This is a writeup of what I found and how I found it, and I tried to do it without ever reading anybody's actual data, which I will get into.
The short version
- Censys turned up 8,402 Qdrant services facing the internet. After deduping by host that came to 6,113 unique boxes, and 5,918 of them actually answered when I knocked.
- Of the ones that answered, 73.5% had no authentication at all. Anybody could list what was inside. 3,047 of them handed over their full collection structure, which came to 32,670 collection names.
- Most of it is harmless hobby stuff, knowledge bases and chatbot memory and test collections. A meaningful slice was not harmless though, I found medical records, legal case files with client names, bank and KYC data, resume databases, and a handful of facial recognition stores, all reachable without a password.
- None of this took any hacking. The databases ship with the lock off and a lot of people never turn it on, and there is nothing that warns them, so it just sits there.
- I ran the same thing against Weaviate to see if it was just a Qdrant problem. It is not, though Weaviate is a bit better, 57.7% of those exposed their schema versus Qdrant's 73.5%. The ones that were open leaned more sensitive though, a lot of law firm data.
Why I bothered
Everybody has been writing about exposed AI lately. There were the big reports on open Ollama instances, tens of thousands of them just running models for anyone who showed up. Censys did a great one on MCP servers, which are the things that give an AI hands to go do stuff. Those got a lot of attention and rightly so.
The piece that got less attention is the memory. An exposed model is a reachable capability, somebody can make it generate text, fine, that is a problem. But the vector database behind a RAG setup is the actual private information somebody fed into it, and that felt like the more interesting thing to count because it is the data itself, not the thing that reads the data.
So to say it plainly again, the Orca team already showed the data inside these is real and sensitive. I did not want to repeat that, and I especially did not want to repeat the part where you read the data, since that is the thing I am asking people not to do. What I tried to add instead is three things they did not focus on. A reproducible way to find and measure these with Censys that anyone can rerun and check. A look at where the exposed ones are hosted and which providers leave them open more often, which turned out to be a real pattern. And a hard line of only ever reading the collection list, never the contents. Smaller scope than Orca on purpose, different angle.
What these look like from outside
Qdrant runs an HTTP API on port 6333. If you hit the root path it tells you its version, and if you hit /collections it gives you back the list of collections it holds, assuming nobody set an API key. That is the whole trick. There is no exploit, you ask the question the API was built to answer and it answers.
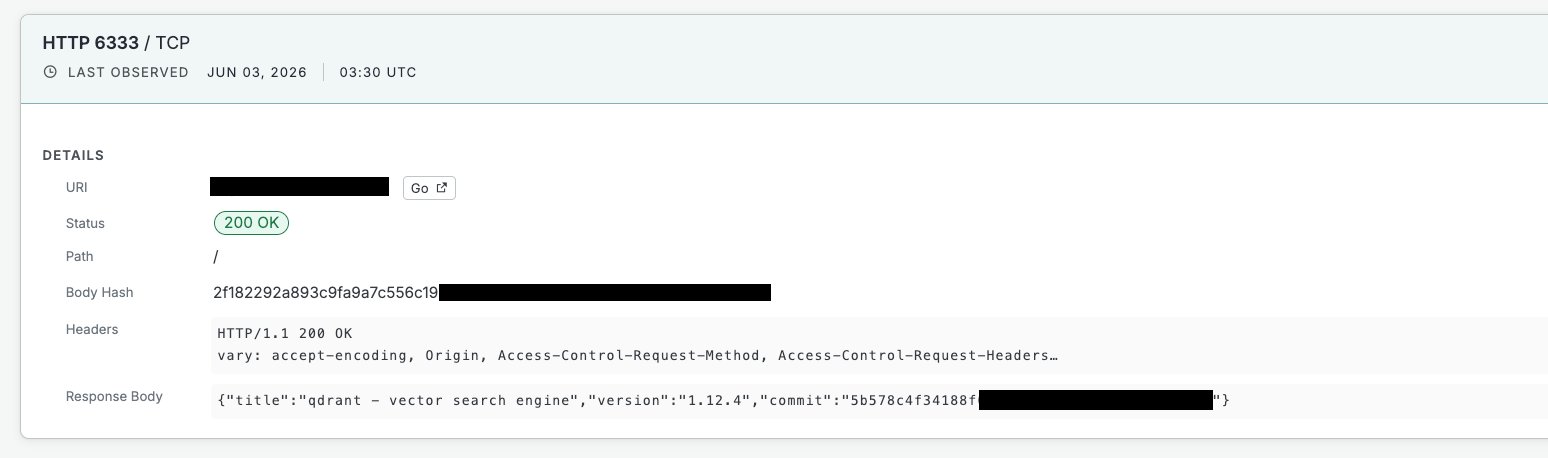
I focused on Qdrant for the deep dive because the fingerprint is clean and the population was big enough to say something real. I also ran the whole thing against Weaviate, which I get to near the end. Chroma I left alone, and there is a reason for that I will explain.
How I did it
Two steps, and they are deliberately boring. First I used Censys to find the hosts. The Platform search caps how deep you can page on a single query, so to get most of the population I sliced the query by autonomous system, grabbing the big hosting providers one at a time and then sweeping up the tail. That got me 6,113 unique IPs.
Second, from a server I rent, I sent each one a single GET to /collections and wrote down what came back. Open with a list, open but empty, asked for auth, or did not answer. I ran it slow, a few requests a second, with a normal user agent that said what it was. The probe never asked for anything past the collection list. If a host returned a 401 or 403 I marked it locked and moved on, no poking.
The reason I ran it from a rented box and not my laptop is partly manners and partly that this is just how you do it, the same way Censys and Shodan are knocking on doors all day. The reason I stopped at the collection list is the important one. Reading the contents of someone else's database is illegal in most places even when the door is open, and it is exactly the harm this writeup is trying to get people to fix, so doing it would have been pretty hypocritical.
The number that matters
Out of 5,918 instances that answered, 4,350 were open and 1,568 wanted a password. Of the open ones, 3,047 actually had collections in them and the other 1,303 were empty, freshly stood up or wiped. So a little over half of everything I reached was unlocked with data structure sitting right there to read.
| Posture | Count | Share of reachable |
|---|---|---|
| Open, no auth | 4,350 | 73.5% |
| with collections | 3,047 | 51.5% |
| empty | 1,303 | 22.0% |
| Auth required | 1,568 | 26.5% |
For what it is worth my early test of 50 hosts came in at 70%, and the full run landed at 73.5%, so the number held up which made me trust it more.
Where these live, and who leaves them open
This is the part I had not seen anybody else break out, so it is the bit I am most happy with. I joined every reachable IP back to its hosting provider and then looked at the open rate per provider. The hosting matters more than I expected.

| Provider | Country | Instances | Open | Open % |
|---|---|---|---|---|
| OVH | FR | 945 | 819 | 87% |
| Contabo | DE | 508 | 393 | 77% |
| AWS | US | 136 | 103 | 76% |
| DigitalOcean | US | 675 | 489 | 72% |
| Hetzner | DE | 857 | 607 | 71% |
| Alibaba Cloud | CN | 251 | 169 | 67% |
| Microsoft Azure | US | 278 | 164 | 59% |
| Google Cloud | US | 246 | 121 | 49% |
So open by default is basically everywhere, but the cheap VPS providers are the worst, OVH at 87% is rough, Contabo and Hetzner are right up there too. The only two that come in clearly below the pack are Google Cloud at 49% and Azure at 59%. My best guess is that the big clouds make you go out of your way to put something on a public IP, there are firewall rules and security groups in the way by default, whereas a five dollar VPS just drops you straight onto the internet with nothing in front of you. So the same person doing the same careless thing ends up exposed on the cheap box and accidentally protected on the expensive one.
One provider stuck out hard. There was an autonomous system, AROSS, with 232 Qdrant instances and every single one of them was open, a 100% rate. When I looked closer they all shared the exact same two collections, knowledge_seo and seo_keywords. That is not 232 different people, that is one outfit running an SEO tool across 232 servers and never locking any of them. More on that pattern in a second.
Geography
The map leans European, which lines up with the hosting since OVH is France and Hetzner and Contabo are Germany. The United States is technically on top by raw count but France and Germany together are way ahead, and that is a different shape than the Ollama and MCP reports which were mostly a US story.
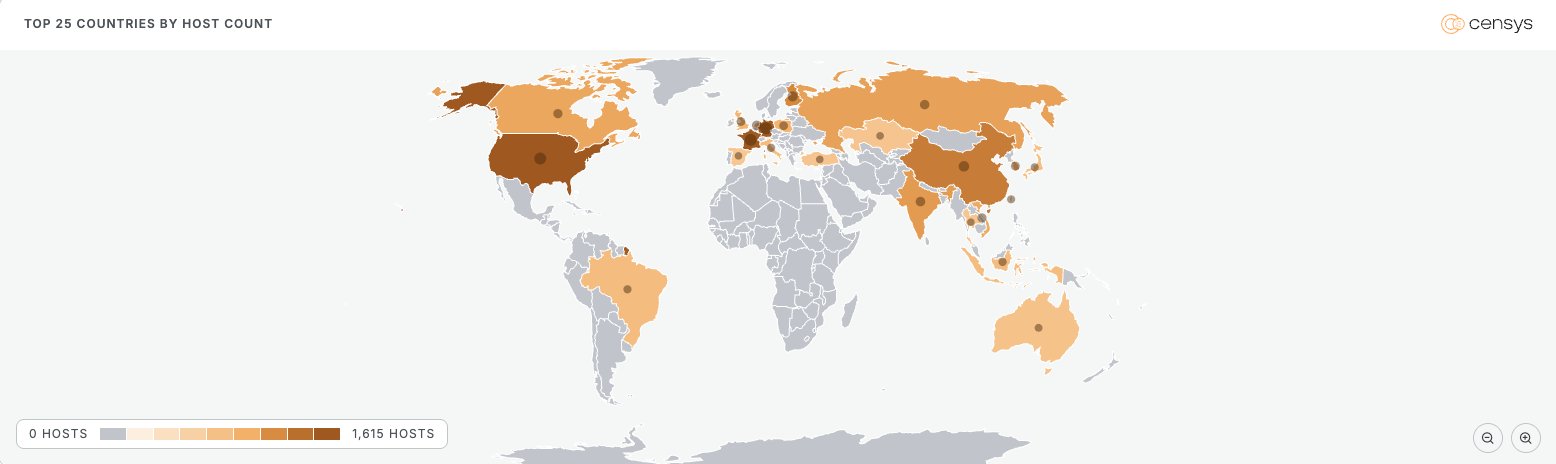
| Country | Hosts | Share |
|---|---|---|
| United States | 1,615 | 19.2% |
| France | 1,559 | 18.6% |
| Germany | 1,544 | 18.4% |
| China | 588 | 7.0% |
| Finland | 424 | 5.1% |
| Singapore | 333 | 4.0% |
| India | 267 | 3.2% |
| Netherlands | 238 | 2.8% |
What people are actually storing
I took all 32,670 collection names from the open instances and bucketed them by what they seem to be, using the names only. This is rough, names lie sometimes and a lot of them are gibberish UUIDs, but the shape is clear enough. Knowledge bases and documents are the big one, then AI agent memory, then a big pile of test and demo and tutorial leftovers.
| Category | Collection names |
|---|---|
| Knowledge base and documents | 6,033 |
| Agent and AI memory | 2,373 |
| Code, technical, test and demo | 2,110 |
| Commerce and product | 1,112 |
| Personal and media | 307 |
| Medical and biometric | 261 |
| Legal | 178 |
| Customer, CRM and sales | 170 |
| Finance | 83 |
| Uncategorized | 20,043 |
The uncategorized pile is mostly random hashes and project specific names that do not match a keyword, that is expected. The categories that should make you wince are the small ones near the bottom, medical, legal, finance, customer data, because those are real people's information and there are hundreds of collections of it sitting open.
The same setup, over and over
I fingerprinted each open instance by hashing its set of collection names, so two instances with the identical set get the same hash. 45 of these clusters had three or more members, which means the same template or the same operator deployed the same thing repeatedly and left it open every time. The SEO outfit with 232 instances was the biggest by a mile. There was also a cluster of facial recognition deployments all named FACES_0 through FACES_3 showing up across a bunch of separate hosts, same idea, one template copied around and never secured.
The ones that made me sit up
Out of the 3,047 open instances with data, 255 had collection names that pretty clearly pointed at sensitive or regulated information, that is about 8.4%. I pulled the full host record for the worst handful to understand what I was looking at. I am not publishing IPs or domains here, because these are real systems that are still open and the whole point is to not make things worse. Descriptions only.
A few that stood out, all open, no auth:
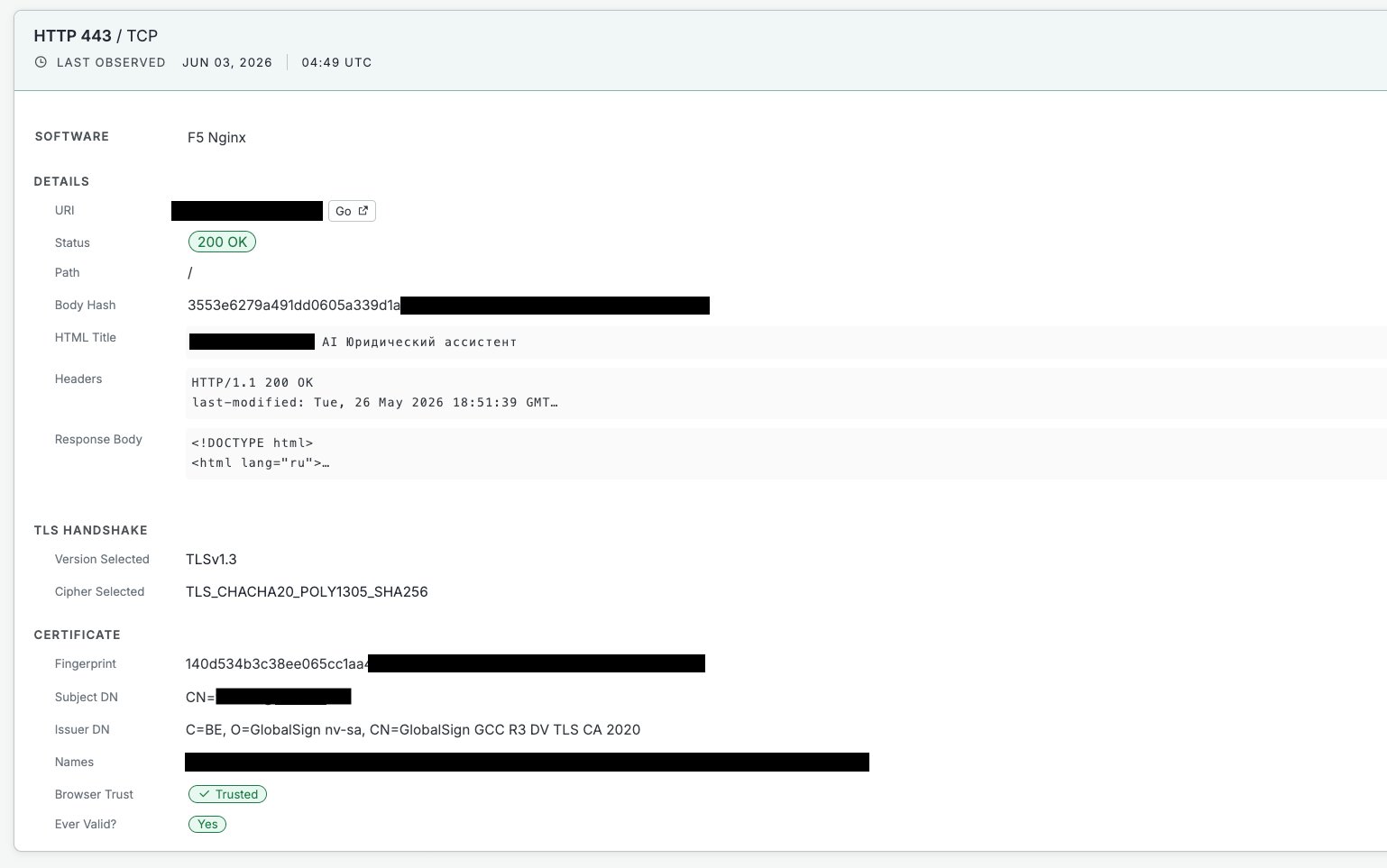
- A box running a combined legal AI and telemedicine operation, with 160 collections mixing medical court case records and legal documents. Same operator, both kinds of data, both reachable.
- A named AI startup's development and staging environment on a major cloud, 333 collections covering bank risk, invoices, and insurance KYC forms, and the vector database was not alone, the document database and the LLM logging tool were sitting open next to it.
- A healthcare platform with 844 collections including clinical knowledge bases, prescription details, and labeled client data.
- A recruiting platform exposing collections full of candidate resumes, which is a tidy pile of applicant PII for anyone who wanted it.
- A facial recognition deployment storing face embeddings, with a database server exposed right beside it.
- An indexing service with bank, resume, and customer collections, and an open SQL Server sitting on the same host for good measure.
The pattern that kept repeating is that the vector database is almost never alone. The careless person who exposed Qdrant usually exposed the whole stack, the model runner, the document store, the dashboard, sometimes a real SQL database, all on the same box. So the vector database exposure is really a symptom of somebody standing up an entire AI setup from a tutorial and never locking any of the doors.
What about the other engines
Qdrant is one vector database out of several, so a fair question is whether it is just unusually careless or whether this is a whole category problem. To check, I pointed the exact same pipeline at Weaviate, another popular self hosted one. Same idea, find them on Censys, probe the listing endpoint, never touch the data.
Weaviate has a clean fingerprint, it answers on port 8080 and its API politely tells you about itself, you can see it in the response pointing at /v1/meta and the schema endpoints. That made it easy to find a trustworthy population, 1,065 in Censys, 1,011 unique after dedup.
One thing about Weaviate that is worth being careful about. Its auth model is different from Qdrant. Qdrant is basically a yes or no, either /collections answers or it does not. Weaviate often lets you read the schema, meaning the list of classes, even on instances that are otherwise locked down, because anonymous schema reads are kind of baked in. So when I say a Weaviate instance was open, I mean its class structure was readable, which is a slightly lower bar than full access. I want to be upfront about that because flattening the two engines into one number would be sloppy.
Even with that softer bar, Weaviate came out more locked down than Qdrant. Of 837 reachable instances, 57.7% exposed their schema and 42.3% wanted auth. Qdrant was 73.5% open. So Weaviate operators are doing better, not great, but better.
| Engine | Probed | Reachable | Open | Sensitive (of open) |
|---|---|---|---|---|
| Qdrant | 6,113 | 5,918 | 73.5% | 8.4% |
| Weaviate | 1,011 | 837 | 57.7% | 17.0% |
Here is the twist though. Weaviate is more locked down overall, but the ones that are open lean more sensitive, 17% of open Weaviate instances had class names pointing at regulated or personal data versus 8.4% for Qdrant. Digging into why, a big chunk of it is legal. There is a cluster of 26 Weaviate hosts all running the same legal AI template, classes named things like LegalText and AgenticCaseMaterialChunk, all open. The same copy and paste deployment problem I saw with the SEO fleet on Qdrant, just pointed at law firms this time.

The class names skew toward knowledge bases and legal rather than the agent memory and chatbot stuff that dominated Qdrant, which makes sense, Weaviate gets pitched more at enterprise search and document use. Versions were spread across 1.24 through 1.34 with nothing dominant.
Why I skipped Chroma
I wanted to do Chroma too, it is the third big name, but I left it out on purpose and I would rather say why than fake a number. Chroma is mostly run embedded, meaning it lives inside a Python process rather than as a network service you can knock on, so the part of it that shows up as an exposed port is small to begin with. On top of that the fingerprint was murky, the broad search was full of false positives because the word chroma shows up in unrelated things, and the tight searches either collapsed to almost nothing or matched generic API paths. I could confirm somewhere between 153 and a few hundred real ones, but I could not get a number I trusted the way I trust the Qdrant and Weaviate ones. So rather than publish a shaky figure I am leaving Chroma as a known gap. If anything the fact that Chroma barely shows up as a network service is itself the interesting bit, the embedded ones are not exposed this way at all.
So what
If these databases shipped with the lock on, or even just yelled at you on startup that you were exposed to the whole internet, most of this would not exist. The fix is genuinely small on each individual box, set an API key, put it behind a firewall, do not bind it to a public IP. The problem is that nobody knows they need to, because everything works fine from where they are sitting and nothing tells them otherwise.
This has happened before with other databases. MongoDB and Elasticsearch had the exact same open by default mess years ago, researchers measured it and made noise, the vendors changed the defaults, and the exposure dropped a lot. Vector databases are sitting right in the middle of that same cycle now. Orca pushed on it, this is me pushing on it a little more, and hopefully a few more people do too, because that is the thing that actually moves a vendor to flip a default. The tooling exploded faster than the security habits did, and there are a few thousand people who have no idea their AI's memory is an open book.
An exposed model is one thing. An exposed vector database is the filing cabinet, and a lot of these filing cabinets have medical records and legal cases and bank data in them, with the drawer hanging open. I did not touch any of it, but I also was almost certainly not the first person to come knocking, and that is the part worth fixing.