A Practical Look at Scraping Behavior
Seeing scraping through traffic behavior
Scraping covers a wide range of behaviors. Some actors rely on simple tools that are blocked quickly and never become part of any meaningful investigation. Others invest more time and skill into staying quiet, blending in, rotating infrastructure, and shaping their traffic so it does not raise obvious alarms. This post focuses on the second group. These are the scrapers that are not immediately blocked, the ones that move carefully, and the ones whose activity you really have to study to understand.
Scraping is often described as a basic interaction repeated many times, but the more advanced operators treat it as an entire workflow. They run their tools across rotating IPs, consistent client fingerprints, predictable patterns, and controlled timing. When you investigate these actors, you are not catching a single request. You are learning to see the underlying behavior that continues long after the first request is made.
The goal in investigations like this is not to rely on one signal or one detection trick. It is to understand the overall behavior well enough that scraping reveals itself through the way it moves through the platform. Once you start to recognize these patterns, even the more sophisticated operators become easier to spot.
I want to walk through how I think about this work. It is not a strict recipe. It is a way of exploring a dataset to understand what is normal, what is unusual, and what is quietly persistent underneath everything else.
Start with the rhythm of the dataset
Before looking at anything specific, I always take a step back and look at the rhythm of the traffic. Every platform has its own feel. When the traffic is healthy, most responses look clean. You see a large portion of successful responses and a smaller portion of natural errors. You also see differences in response sizes that match the type of content being served.
The reason I start here is simple. Scraping rarely introduces strange codes or dramatic errors. The more capable actors do everything they can to avoid problems. They tune their tools to stay within limits. They adjust timing based on responses. They run with fewer mistakes because mistakes slow them down.
When the global view makes sense, I know I can trust the rest of the dataset.
Understand where the traffic flows
Once the broad picture looks steady, I begin to look at what surfaces are being hit. Most logged-out browsing spreads nicely across a platform's offerings. The variety itself is a useful signal.
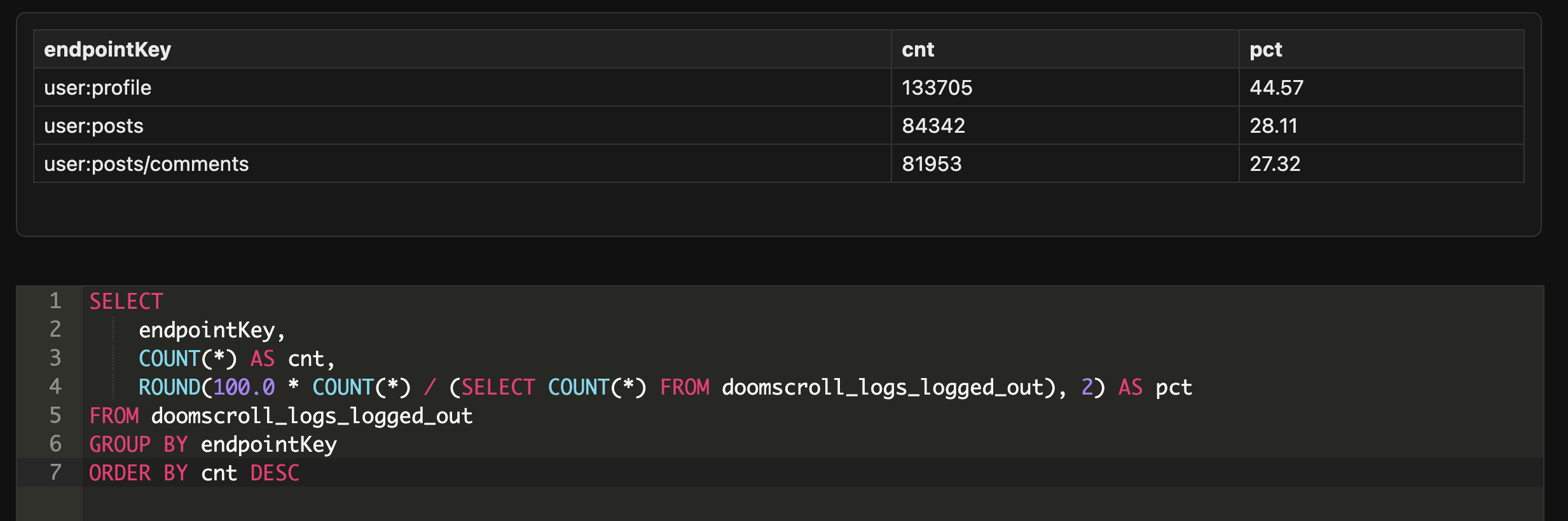
Scraping does not usually have that variety. It tends to focus on a particular resource or a small group of them. Something like repeated profile access or repeated content fetches without any of the natural wandering you see in real users.
I never assume intent at this point. I am simply paying attention to the shape of the traffic. If I see a client that does nothing but one endpoint, that is worth remembering for later.
Get a sense of the clients themselves
This is where multiple signals start to come together. I do not rely on one thing. A single client fingerprint is never enough. Instead, I look at the full blend of evidence.
Browser-based fingerprints like JA4 help show me whether a request looks like a real desktop browser, a mobile app, a script, or something custom. Patterns in SSL/TLS can reveal how a client handles handshakes, which versions it prefers, and how consistent it is across connections. Real browsers have quirks that come from their underlying libraries and update cycles. Automated actors often have a different feel because their tooling stays fixed for long periods of time.
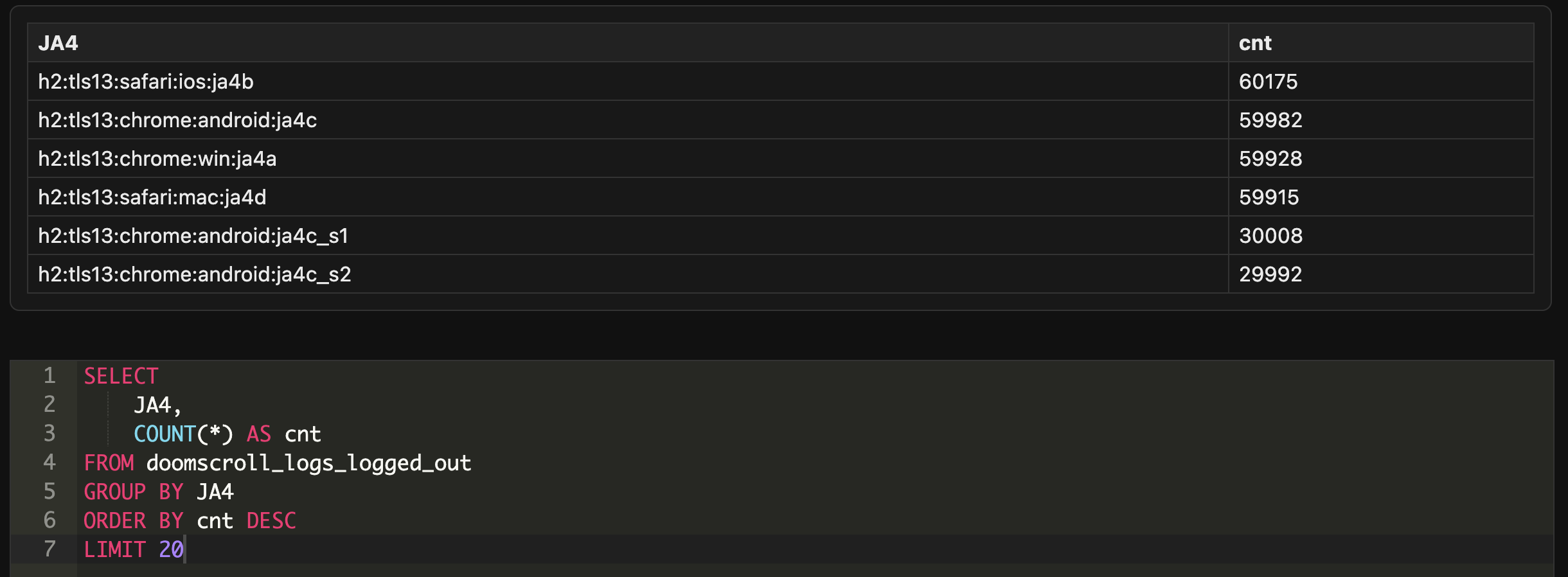
IP behavior also plays a role. In a normal dataset, you see a long tail of low-volume IPs and a few that are busy because of families, offices, or public networks. In scraping operations, the activity can look entirely different. You might see dozens or hundreds of IPs sharing the same client fingerprint. You might see a cluster of addresses belonging to a particular hosting provider. You might see a pattern where nothing stands out individually, but the combined behavior clearly pushes past what a real user would do.
I never draw conclusions here. I just gather signals and see which ones align.
Look at how the clients handle volume and pressure
Real people do not browse with perfect timing or specific targets. They pause, scroll, click around, and get distracted. Automated scraping tools move with a different kind of precision. Their requests arrive with smoother spacing, fewer natural mistakes, and more predictable interactions with rate limits or friction points.
One of the more useful parts of this work is watching how a client responds when the platform pushes back on them. Do they slow down. Do they back off. Do they retry aggressively. Do they switch IPs. Do they rotate certificates or JA4 settings. Do they adjust user agents. The reaction is often more revealing than the request itself.
If an actor is rotating IPs very quickly, that usually tells you they care about potentially hiding volume or bypassing security defenses. If they keep the same fingerprint but spread the work across many networks, that tells you they want consistency on the client side while keeping the infrastructure fluid. When you combine these small details, the behavior becomes clearer.
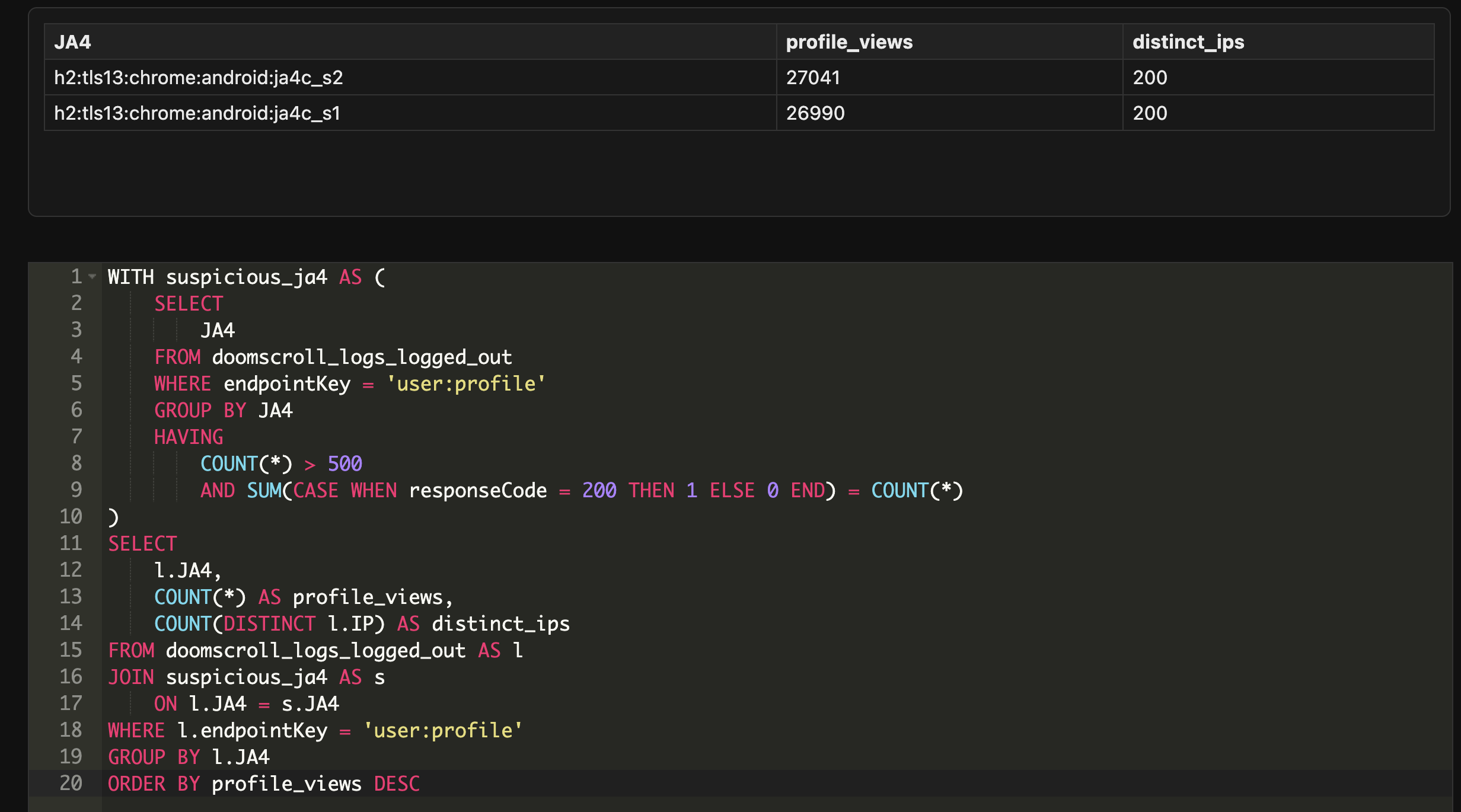
Bring the pieces together and look at the pattern as a whole
The most important part of a scraping investigation is understanding that no single signal tells the entire story. You need to look at everything together.
- A suspicious fingerprint might not matter if the endpoint usage looks normal.
- A large amount of traffic might not matter if the timing looks natural.
- A cluster of hosting provider IPs might not matter if the success rate is low.
But when a single client fingerprint shows heavy usage on a limited set of endpoints, across many IPs, with consistent SSL/TLS behavior, and with clean response spikes after small amounts of failures dips, you have a behavior that is no longer accidental. It is intentional, structured, and consistent with automated collection.
Once you reach this view, you can tell the story in a way that is supported by evidence. You can describe how the traffic flows, how the client behaves, how the infrastructure rotates, and how the results point toward scraping rather than normal browsing.
The value is in the behavior, not the individual requests
Scraping is not only a single event. Scraping is also patterns. It is a style of movement within the traffic. It shows itself through repetition, precision, and structure. You find scraping by understanding the differences between natural human behavior and the steady, deliberate steps of automation.
The more datasets you study, the easier it becomes to see the shape underneath the noise. Over time, scraping stops looking like a mystery and starts looking like a pattern in the traffic that reveals its own story if you read it closely enough.